PanjehCompiling OpenMP on MacOSNote: Apple does not include OpenMP in the clang they ship, and the gcc in mac os is just an alias to clangJul 5, 2021Jul 5, 2021
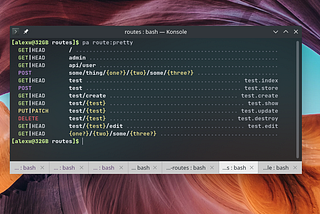
PanjehPretty Laravel Routes in consoleThis package pretty-routes add a route:pretty command to your artisan console for pretty route output.Apr 28, 2021Apr 28, 2021
PanjehHow to convert ipynb to PythonHow to run an .ipynb Jupyter Notebook from terminalApr 22, 2021Apr 22, 2021
PanjehCheck whether a numpy array is empty or not?Numpy array has .size attribute. If it returns zero it means there are no elements in the array.Apr 22, 2021Apr 22, 2021
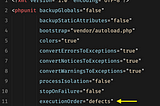
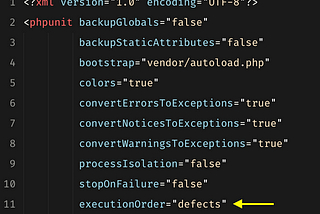
PanjehFirst Run Failed Tests in Laravel phpFor phpunit test you need config a phpunit.xml file. You can set this little config in phpunit.xml and see how in the next run your, last…Mar 28, 2021Mar 28, 2021
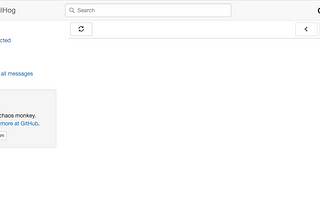
PanjehSetup MailHog with Laravel valet localhost or Laravel SailInstalling MailHogMar 15, 20212Mar 15, 20212
PanjehHow to handle enums in Laravel databaseSuppose there are two models Patient and also Exam and the relationship between them is One To Many, I mean each patient can have many…Mar 13, 2021Mar 13, 2021
PanjehLaravel routes controller action declarationI’ve just installed Laravel 8 besides Laravel Breeze and in auth.php file in the routes directory, I see how we should import the…Mar 5, 2021Mar 5, 2021